|
Kun-Yu Lin I am now a post-doctoral research fellow at the University of Hong Kong, under the supervision of Prof. Kai Han. I earned my PhD degree from Sun Yat-sen University, under the supervision of Prof. Wei-Shi Zheng. Before that, I received my Bachelor's degree and Master's degree from Sun Yat-Sen University. During my PhD, I was fortunate to have the opportunity to study as a visiting student at MMLab@NTU, under the supervision of Prof. Chen Change Loy and Prof. Henghui Ding. My research interests include computer vision and machine learning. |

|
News |
| ❅ 10/2025: Honored to be selected as a Top Reviewer in NeurIPS25. |
| ❅ 09/2025: Two papers were accepted to NeurIPS25. |
| ❅ 07/2025: One paper was accepted to TPAMI. |
| ❅ 06/2025: Three papers were accepted to ICCV25. |
| ❅ 05/2025: Releasing Panoptic Captioning, a novel captioning task to seek the minimum text equivalent of images. |
| ❅ 02/2025: Four papers were accepted to CVPR2025. Sincerely congratulations to Jiaming, Yi-Xing, Yu and Wei-Jin. |
| ❅ 12/2024: One paper was accepted to AAAI2025. |
| ❅ 07/2024: One paper was accepted to TPAMI. |
| ❅ 03/2024: Releasing XOV-Action, the first cross-domain open-vocabulary action recognition benchmark! |
| ❅ 09/2023: One paper was accepted to NeurIPS2023. |
| ❅ 09/2023: One paper was accepted to TPAMI. |
| ❅ 07/2023: One paper was accepted to ICCV2023. |
| ❅ 03/2023: Two papers were accepted to CVPR2023. |
Selected WorksMost of my research works are about video understanding, trustworthy deep learning, and vision-language models. Some works are highlighted. # denotes equal contributions. * denotes corresponding author. |

|
Panoptic Captioning: An Equivalence Bridge for Image and Text
Kun-Yu Lin, Hongjun Wang, Weining Ren, Kai Han* NeurIPS, 2025 paper / arXiv / project page / github A novel vision-language task, named panoptic captioning, leading to comprehensive text representations to seek the conceptual minimum text equivalent of images. |
|
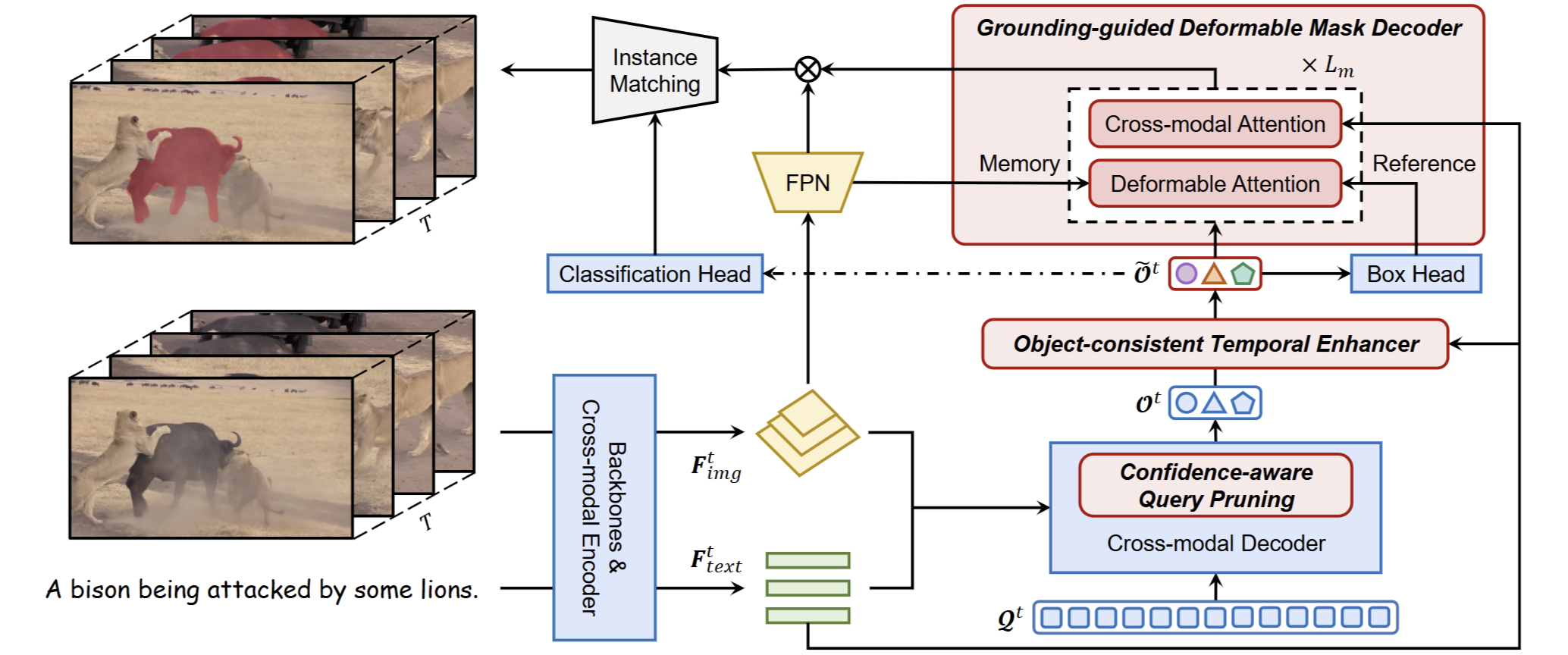
ReferDINO: Referring Video Object Segmentation with Visual Grounding Foundations
Tianming Liang, Kun-Yu Lin, Chaolei Tan, Jianguo Zhang, Wei-Shi Zheng, Jian-Fang Hu* ICCV, 2025 paper / arXiv / project page / github A strong referring video object segmentation model based on visual grounding foundations. The core of the runner-up solution for the PVUW Challenge RVOS Track at CVPR 2025. |

|
Exploring the Limits of Vision-Language-Action Manipulations in Cross-task Generalization
Jiaming Zhou, Ke Ye, Jiayi Liu, Teli Ma, Zifan Wang, Ronghe Qiu, Kun-Yu Lin, Zhilin Zhao, Junwei Liang* NeurIPS, 2025 paper / arXiv / project page / github A cross-task manipulation generalization benchmark to evaluate existing Vision-Language-Action (VLA) models, and a novel generalizable VLA method. |
|
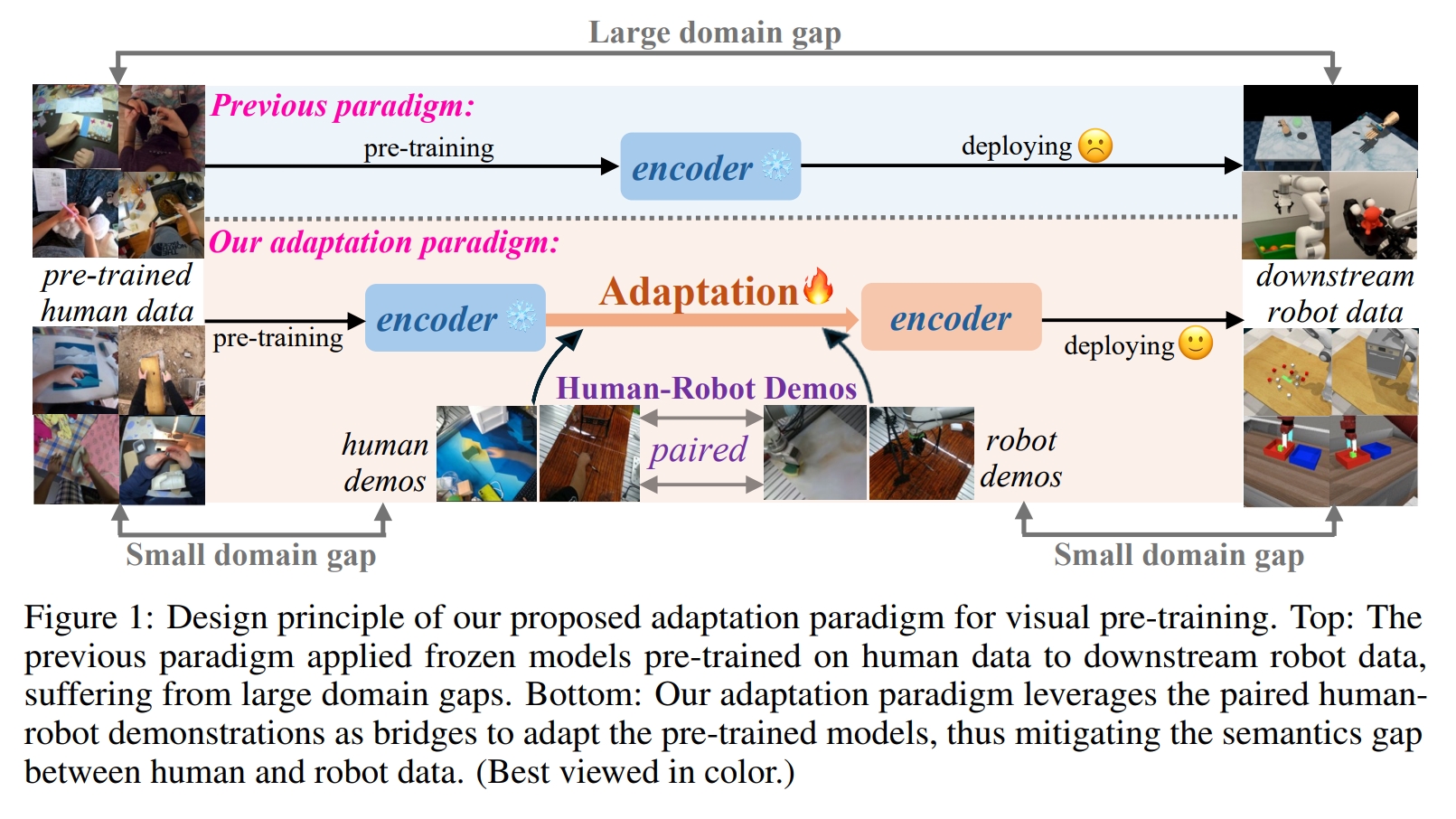
Mitigating the Human-Robot Domain Discrepancy in Visual Pre-training for Robotic Manipulation
Jiaming Zhou, Teli Ma, Kun-Yu Lin, Ronghe Qiu, Zifan Wang, Junwei Liang* CVPR, 2025 paper / arXiv / project page / github A new paradigm, utilizing paired human-robot videos, to adapt human-data pretrained models for robotic manipulation. |
|
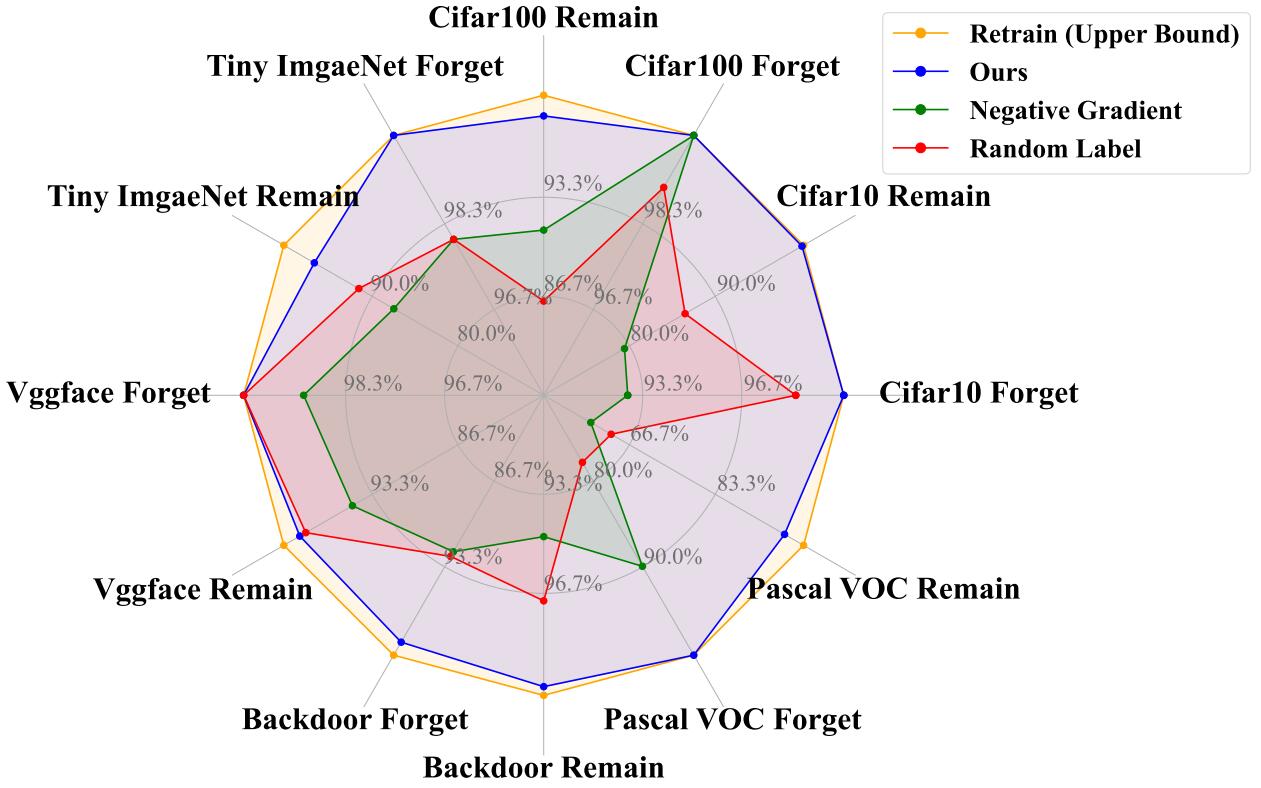
Decoupled Distillation to Erase: A General Unlearning Method for Any Class-centric Tasks
Yu Zhou#, Dian Zheng#, Qijie Mo, Renjie Lu, Kun-Yu Lin*, Wei-Shi Zheng* CVPR, 2025, Highlight paper / arXiv A general unlearning solution for any class-centric tasks, without using any retained data and any pretrained model knowledge. |
|
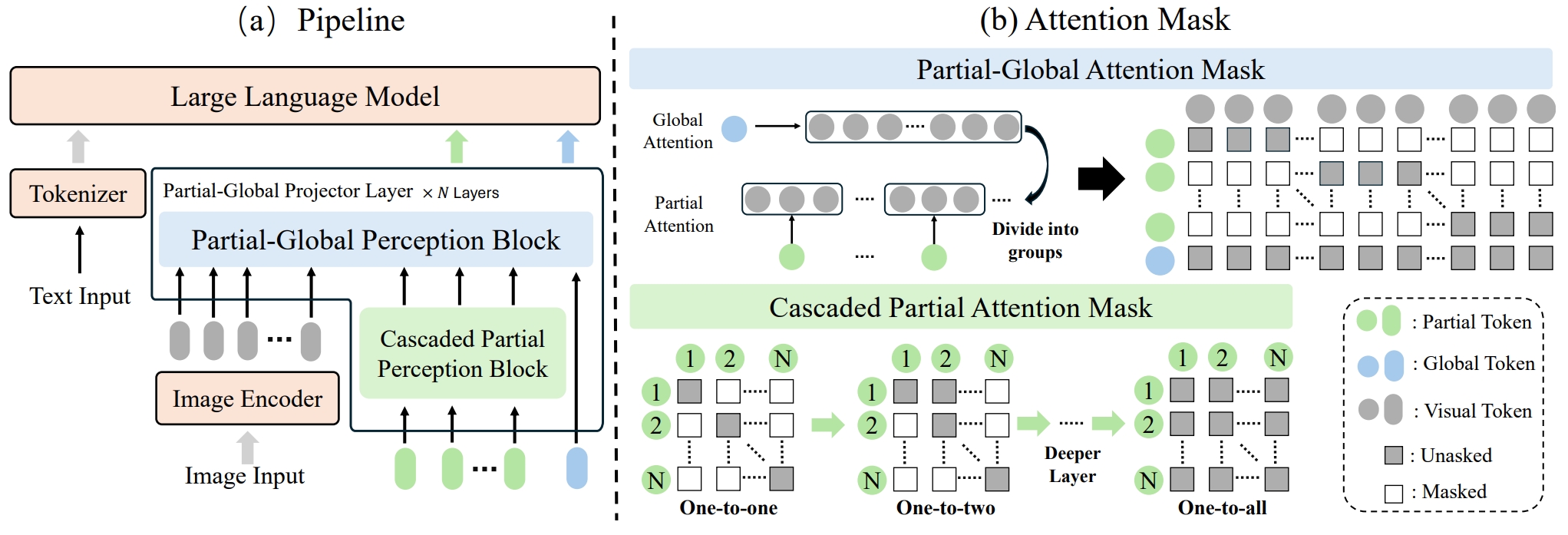
ParGo: Bridging Vision-Language with Partial and Global Views
An-Lan Wang, Bin Shan, Wei Shi, Kun-Yu Lin, Xiang Fei, Guozhi Tang, Lei Liao, Jingqun Tang, Can Huang, Wei-Shi Zheng* AAAI, 2025 paper / arXiv / github A novel connector for bridging vision and language modalities by leveraging both global and partial views, and a large-scale image-text datasets consisting of detailed captions. |
|
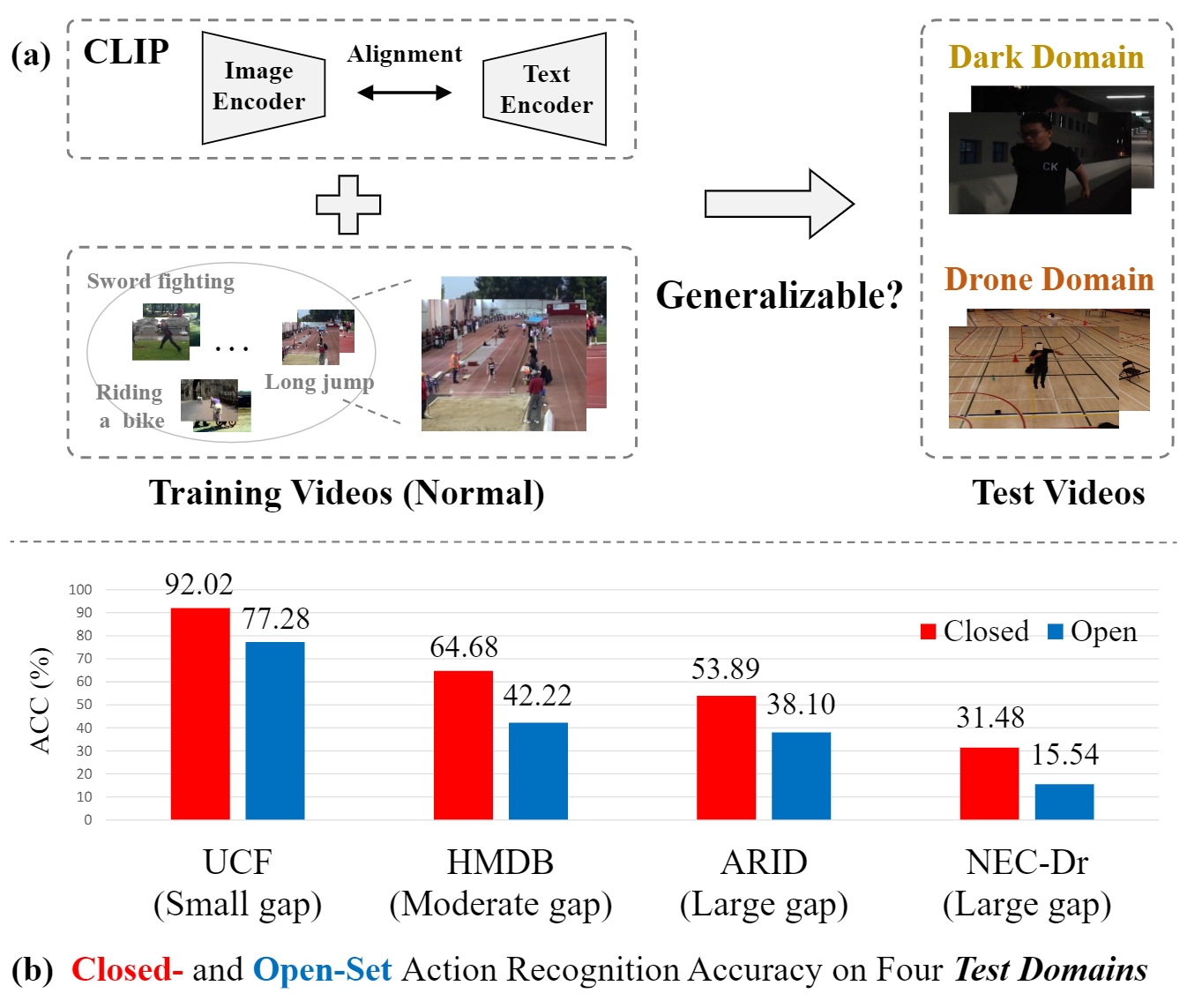
Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Kun-Yu Lin, Henghui Ding, Jiaming Zhou, Yu-Ming Tang, Yi-Xing Peng, Zhilin Zhao, Chen Change Loy, Wei-Shi Zheng arXiv, 2024 arXiv / github The first benchmark, named XOV-Action, for the cross-domain open-vocabulary action recognition task, and a simple yet effective method to address the scene bias for the task. |
|
|
Human-Centric Transformer for Domain Adaptive Action Recognition
Kun-Yu Lin, Jiaming Zhou, Wei-Shi Zheng* TPAMI, 2025 paper / arXiv A human-centric video network to address the context bias in domain adaptive action recognition. |
|
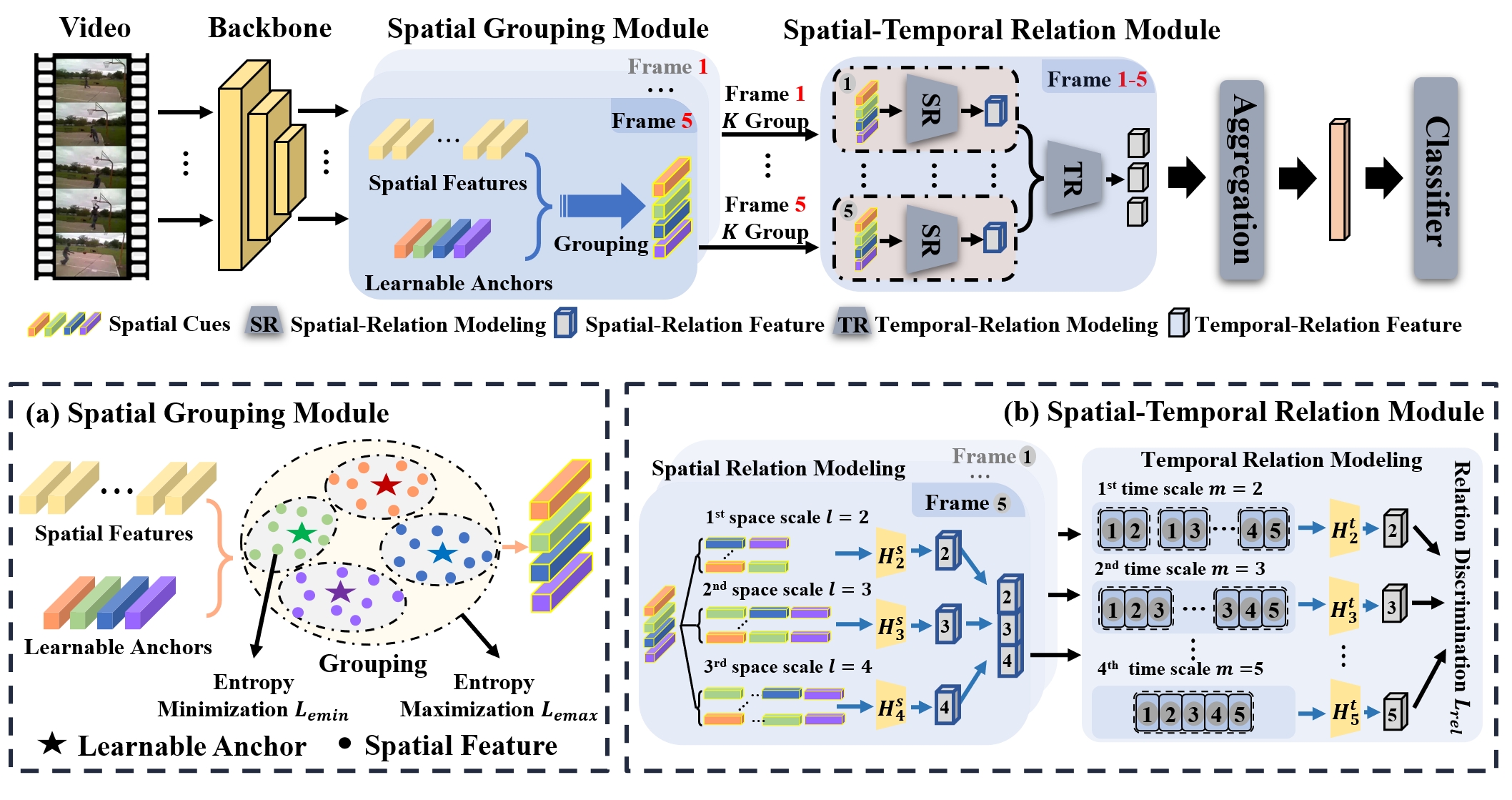
Diversifying Spatial-Temporal Perception for Video Domain Generalization
Kun-Yu Lin, Jia-Run Du, Yipeng Gao, Jiaming Zhou, Wei-Shi Zheng* NeurIPS, 2023 paper / arXiv / github A diversity-aware video network to address domain-specific bias in video domain generalization. |
|
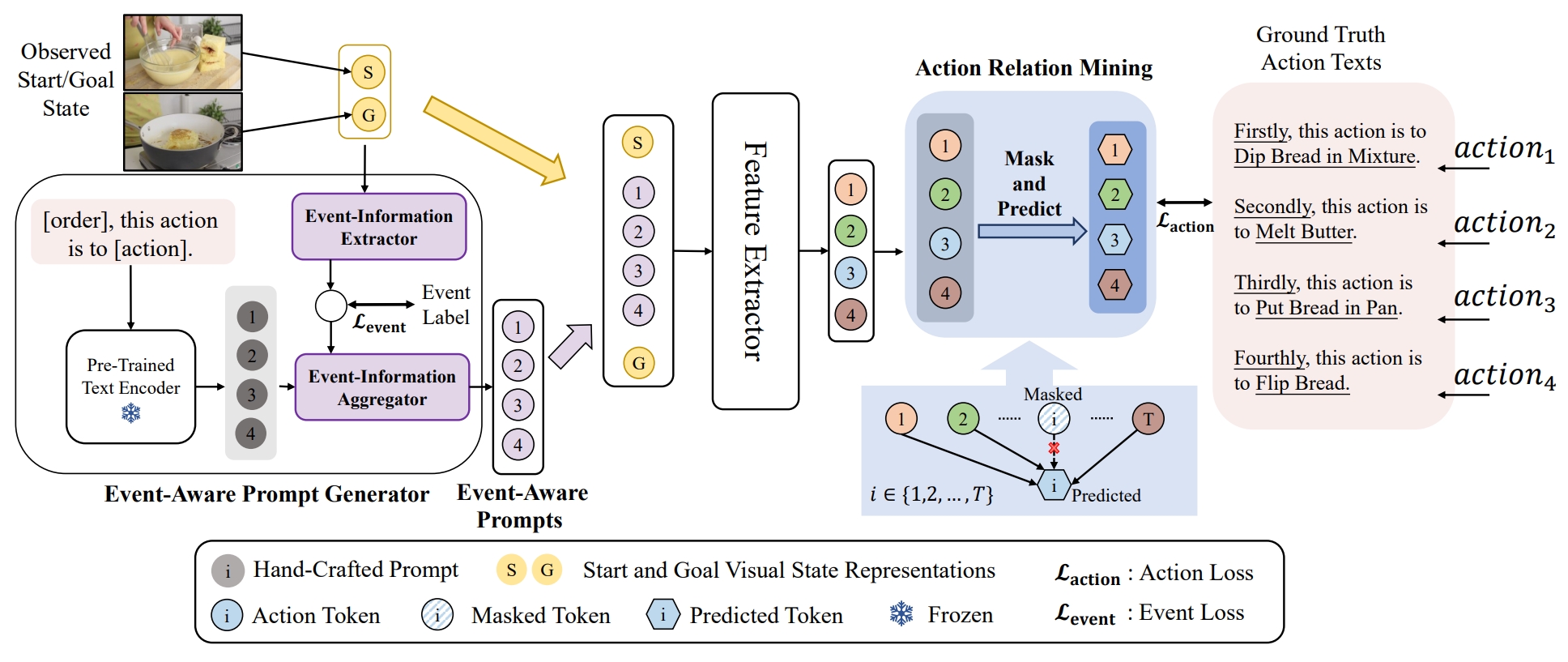
Event-Guided Procedure Planning from Instructional Videos with Text Supervision
An-Lan Wang#, Kun-Yu Lin#, Jia-Run Du, Jingke Meng*, Wei-Shi Zheng* ICCV, 2023 paper / arXiv A new event-guided paradigm to address the semantic gap between observed states and unobserved actions for procedure planning in instructional videos. |
|
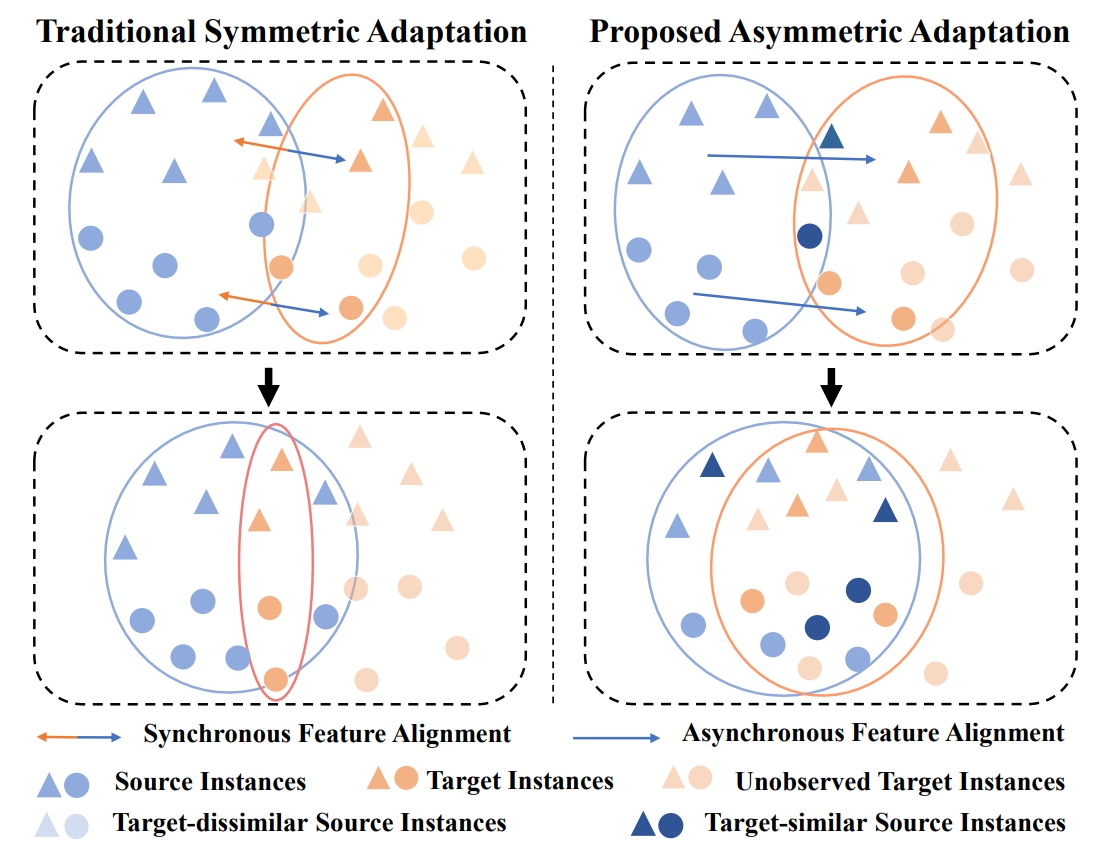
AsyFOD: An Asymmetric Adaptation Paradigm for Few-Shot Domain Adaptive Object Detection
Yipeng Gao#, Kun-Yu Lin#, Junkai Yan, Yaowei Wang, Wei-Shi Zheng* CVPR, 2023 paper / github An asymmetric adaptation paradigm for few-shot domain adaptive object detection. |
|
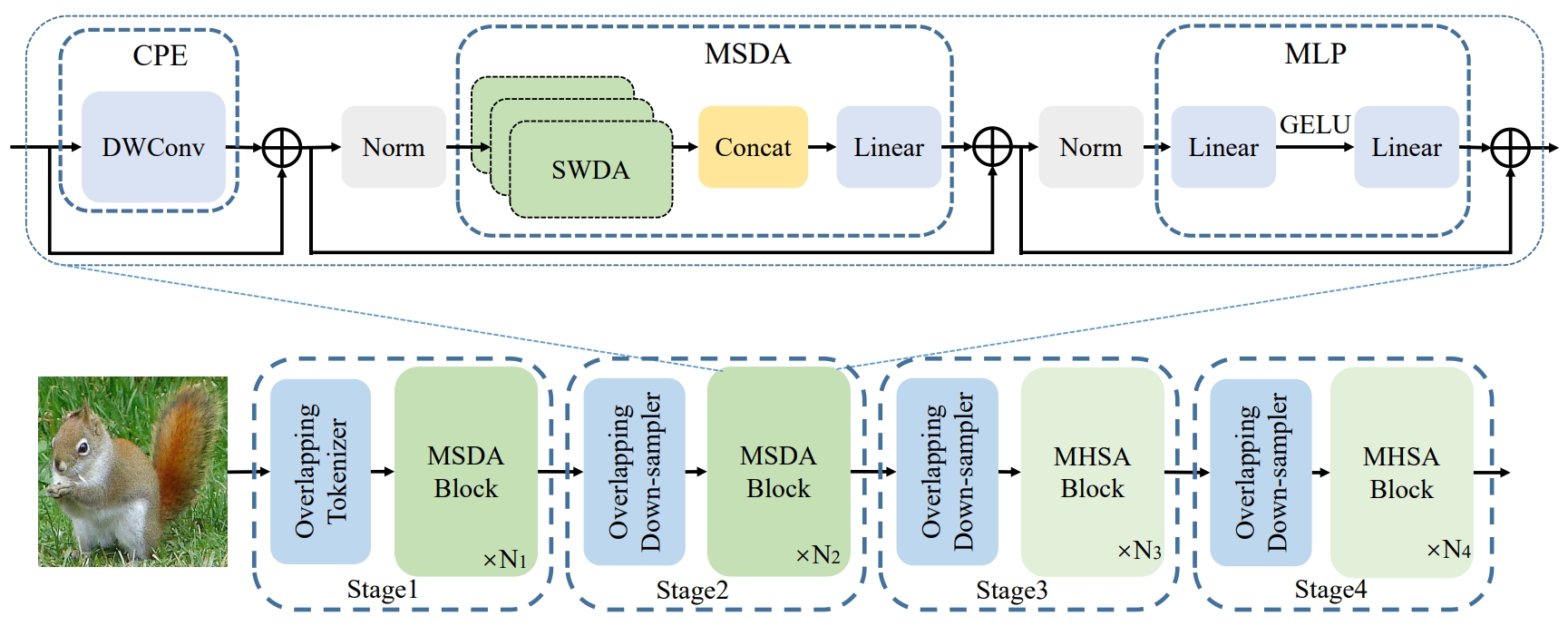
DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition
Jiayu Jiao#, Yu-Ming Tang#, Kun-Yu Lin, Yipeng Gao, Jinhua Ma, Yaowei Wang, Wei-Shi Zheng* TMM, 2023 paper / arXiv / project page / github A new vision transformer architecture for efficient and effective visual understanding. |

|
Supervision Adaptation Balancing In-distribution Generalization and Out-of-distribution Detection
Zhilin Zhao, Longbing Cao, Kun-Yu Lin TPAMI, 2023 paper / arxiv / github A theorectical method to balancing in-distribution generalization and out-of-distribution detection. |

|
Revealing the Distributional Vulnerability of Discriminators by Implicit Generators
Zhilin Zhao, Longbing Cao, Kun-Yu Lin TPAMI, 2023 paper / arxiv / github A theorectical method based on implicit generators to improve out-of-distribution detection. |
|
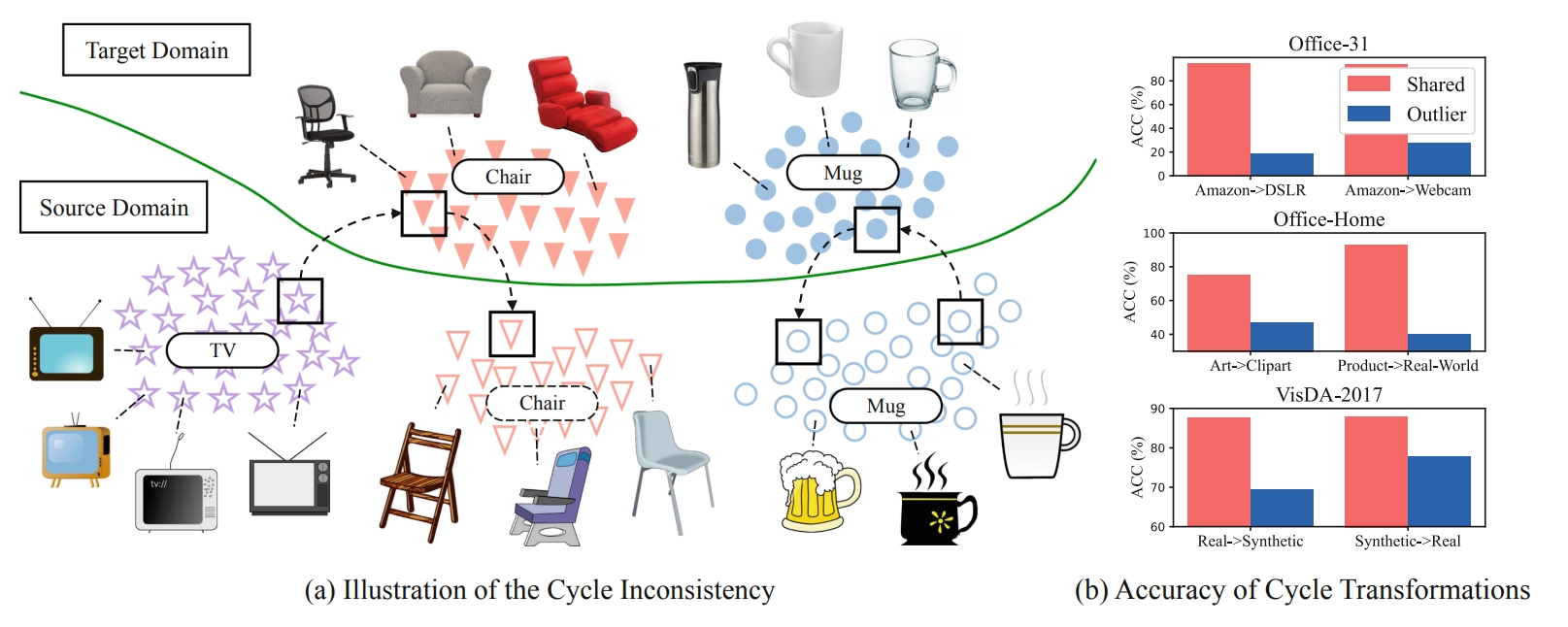
Adversarial Partial Domain Adaptation by Cycle Inconsistency
Kun-Yu Lin, Jiaming Zhou, Yukun Qiu, Wei-Shi Zheng* ECCV, 2022 paper / github A simple yet effective method based on cycle transformation to filter out outlier classes in partial domain adaptation. |
Services |
 |
Reviewer of CVPR23, CVPR24, CVPR25, CVPR26
Reviewer of ICCV23, ICCV25 Reviewer of ECCV24, ECCV26 Reviewer of ICLR25 Reviewer of NeurIPS24, NeurIPS25 Reviewer of ICML26 Reviewer of TPAMI Reviewer of IJCV |
|
This website borrows from Jon Barron. |